PAI-Rec选型主要包括如下两个部分:
一、服务选型
为便于开发者更加便捷地使用服务,将为企业开发者提供3种不同的推荐算法服务。
序号 | 服务类型 | 说明 | 目录价 |
1 | 标准版服务 | 推荐引擎配置 服务发布管理 指标注册与自定义、实验报表 AB实验平台、推荐数据排查工具 一致性检查工具 | 5000元/月 |
2 | 高级版服务 | 较标准版新增加: 数据智能诊断 推荐算法定制(配置产出召回、特征工程、排序代码,一键部署,新物品冷启动等功能) | 8000元/月 |
3 | 增值功能 | 定向运营(流量调控、物品封禁和置顶、定坑) | 1000元/月 |
若开发者使用的算法服务为行业标准配置、或者自行完成算法组装,将无需支付额外的费用。 若需要根据场景定制,设计链路配置,模型选型,按照效果交付调优等,则需进行商务洽谈后支付定制人天费用。
初次接入服务,建议优先选择高级版服务接入,因为高级版本中包含数据诊断和推荐算法定制功能。通过数据诊断可以分析用户特征、物品特征中特征的有效性,分析用户行为表是否正确,并且决定推荐算法定制中的特征和排序模型等参数。推荐算法定制可以帮助用户生成相关代码,快速产出召回和排序相关的数据和模型,并一键部署。
二、资源选型
构建完整的推荐系统,需要一些划分相对独立的数据模块、算法模块、在线链路模块等,需要按照开发习惯、现有业务系统的数据架构,选择合适的资源拼装选型。
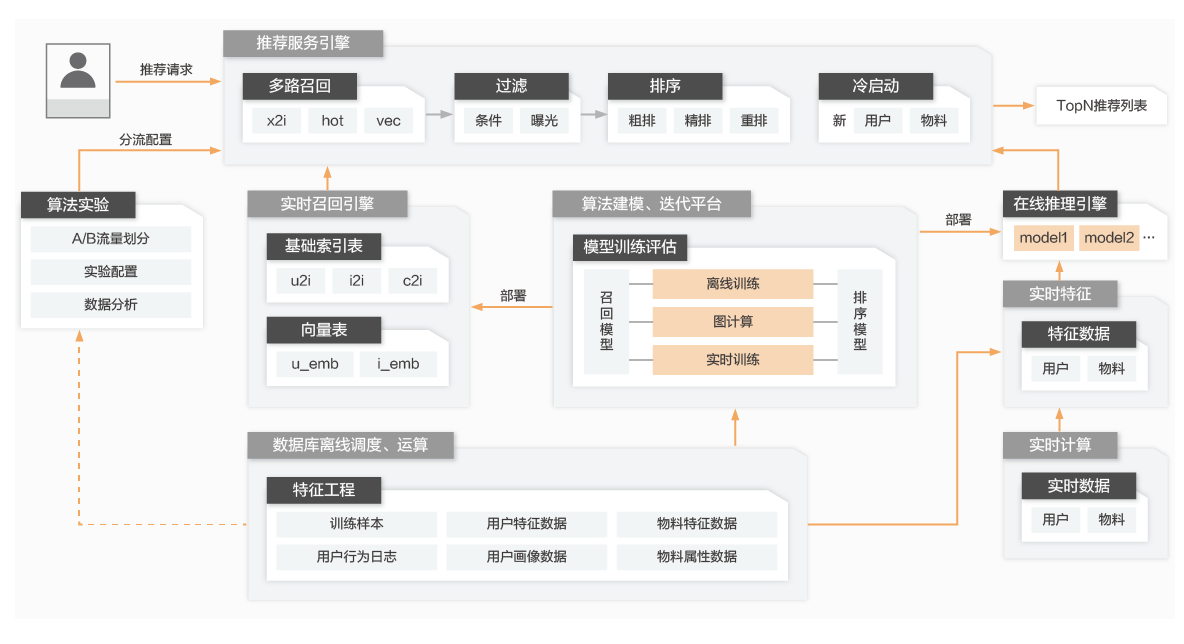 基于大数据开发实践,我们建议的选型为:
基于大数据开发实践,我们建议的选型为:
序号 | 模块/用途 | 云服务 |
1 | 建模、数据清洗、任务调度等 | 机器学习PAI、大数据开发治理平台DataWorks、 云原生大数据计算服务MaxCompute |
2 | 模型存储 | 对象存储OSS |
3 | 实时特征存储引擎 向量召回引擎 | Hologres 图计算GraphCompute |
4 | 在线预测引擎 | 在线预测服务(PAI-EAS) |
此外,为保证服务的便捷运维,数据便捷回流,以及后续代码级更加灵活的开发,我们建议开通如下服务:
序号 | 模块/用途 | 云服务 |
1 | 数据总线DataHub | 用于实时日志回流,持续更新用户行为,用于模型训练 |
2 | 日志服务SLS | 用户请求日志将推送至SLS服务,可前往SLS服务管理运维 |
3 | 容器镜像服务 |
|
选型方案建议
基于客户不同的业务现状和需求可开通不同的资源组合,不同的算法组合也影响需要的资源。
此处的DAU规模仅为预估,不是一个严格的分界线,主要是基于提高推荐效果是否能带来足够的业务价值,以覆盖推荐系统的成本。
以小于5万的方案为基准,下面的方案都是在上一方案基础上的变化。
DAU规模 | 召回模型建议 | 排序模型建议 | 用户特征存储建议 |
DAU小于5万 | 不使用向量召回模型,可不部署向量召回引擎 | 使用相对简单的单目标多塔模型,推理速度快效果比较好,同时节约PAI-EAS的资源。 使用MaxCompute预付费资源,做特征工程、样本处理、深度学习模型训练 | 通过Flink写入到Redis中。 |
DAU大于5万 | 可以增加向量召回。所有特征存储、向量查询都使用Hologres产品。 | 使用多目标排序模型。 | 当用户特征快速变化的情况,可考虑Graphcompute |
DAU大于20万 | 用户向量的实时推理 物品冷启动算法,如协同度量学习算法 | 建议使用增量训练节约训练成本。 建议增加物品实时特征。 | 可以考虑Graphcompute |
DAU大于50万 | 如果经常有活动影响推荐系统的效果,可以考虑增加在线学习的方案。 即通过Flink实时拼接样本,在线学习模型并且每天多次更新线上的模型。 | 可考虑预付费的MaxCompute资源。 | |
当新物品较多:
建议使用物品冷启动算法,让新物品分发更加合理。
当需要调控指定物品、指定类目的流量:
建议使用流量调控的算法,按照物品、物品集合、物品类目来调整曝光流量数量、曝光占比。
其他建议:
用户特征数量多:可以尝试把用户特征存储在OTS(表格存储)。
PAI-EAS:注意在业务高峰期配置定时扩容,同时配置自动缩容保证到业务低峰期收缩资源。
PAI-EAS打分服务:可考虑预付费资源和弹性扩缩容资源相结合。
用户有社交关系:建议使用GraphCompute管理用户之间的关注、好友关系。有社交关系的推荐场景建议使用GraphSage等图算法。